
Understand Analytic Ingestion
About Analytic Ingestion Services
Application Analytics provides specific REST API services to upload or ingest your analytic logic, template definitions, and deployments simultaneously.
You can use either the Analytic UI or any REST client such as Postman to perform the ingestion. However, before you can prepare the .zip file for upload, it is important to understand the configuration, schema definitions, and structure for the expected file for upload or ingestion.
Essentials Analytics has three API endpoints, facilitating three different methods of analytic data ingestion.
| Service Endpoint | Description |
|---|---|
| /analytics/ingestions | This facilitates ingesting all analytic-related data to run deployments. This method requires you to ingest the analytic template, template configurations including supporting files, input, output, and output event definitions. This also requires you to ingest deployment configurations required to run the deployment in the specified analytic runtime. Note: Currently this method is only available through the service endpoint. Ingesting through the Analytic UI does not use this endpoint. |
| /analyticEntries/ingestions | This facilitates ingesting the following files:
|
/deployments/ingestions | This facilitates ingesting deployment configurations only. This assumes that you have already pre-ingested at least one analytic template for which you can add and configure deployments. This requires you to ingest deployment configurations required to run the deployment in the specified analytic runtime. Note: Currently this method is only available through the service endpoint. Ingesting through the Analytic UI does not use this endpoint. |
Expected Folder Structure
The following diagram represents the expected file and folder structure for an analytic ingestion .zip file. All folders and files indicated below are required for ingestion through the /analytics/ingestions endpoint. The diagram indicates the required folders and files for ingestion through the /analyticEntries/ingestions endpoints in blue. It indicates required folders and files for ingestion through the /deployments/ingestions endpoint in teal.
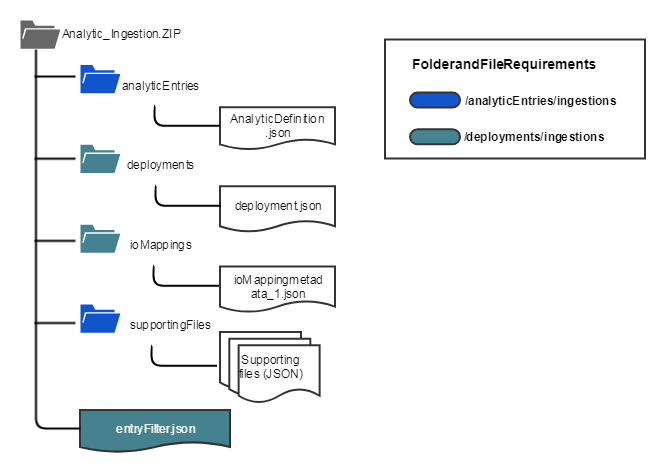
Schema Definition for Analytic Ingestion Files
Each analytic .json file intended to be uploaded through the analytic ingestion services must conform to the respective schemas represented in this document.
AnalyticDefinition.json
This file defines the ingestion metadata contract for AnalyticEntry. This file contains the metadata information for the analytic template such as name, URI, author, and contract version. It also has the analytic template configuration and definitions including inputs, outputs, constants, and supporting files with relative paths to the analytic definition file. Application Analytics does not validate the file name uniqueness and expects the user to keep track of file names. The analytic template metadata and configurations file, for example, analyticdefinition.json, must be placed inside the analyticEntries folder.
The following code snippet indicates the JSON structure with required (mandatory) field configurations. The file must conform to the schema indicated in the code snippet.
{
"@type": "analyticEntrySsRmMetaData", /* analyticEntrySsRmMetaData is for RM, analyticEntrySsMetaData for MEH , analyticEntrySparkMetaData for Spark*/ //Mandatory
"contractVersion":"1.0.0", // Mandatory
"name": "Analytic1", //Mandatory
"uri": "/analytics/16a47853-0804-4972-ac33-b16d33336352", // Not always required. In case of Smart Signal, this is provided. CAF preserves it. Mandatory for SmartSignal
"author": "GE Digital - Smart Signal Analytics Team", //Mandatory
"description": "This is UC_Temperature_Asset's description:",
"analyticRuntimeType": "SmartSignal", /* will be Smart Signal */ //Mandatory, Same for bith MEH and RM
"primaryCategory": "Supervised Learning", //Mandator
"secondaryCategory": "Supervised Learning", /* OPTIONAL */
"analyticVersion": "1.0.0",
"hasAnalyticArtifact": false, //Mandatatory
"analyticArtifact": { //Mandatory
"language": "SmartSignal",
"languageVersion": "v1"
},
"executeParams": { // This is specific to Smart Signal and execute Params are not required. CAF uses this as a default for Smart Signal deployments.
"repeatData": {
"timeValue": 1,
"timeUnit": "MINUTES"
}
},
"isReadyOnly": true
// START Mandatory
"analyticDefine": {
"supportingFiles": [
{
"filename": "../supportingFiles/blueprint.json",
"description": "This is UC_Temperature_Asset's description:"
},
{
"filename": "../supportingFiles/modeblueprints.json",
"description": "Mode Blueprints"
},
{
"filename": "../supportingFiles/modelblueprints.json",
"description": "Model Blueprints"
},
{
"filename": "../supportingFiles/assetblueprinttags.json",
"description": "Asset Blueprint Tags"
},
{
"filename": "../supportingFiles/modelblueprinttags.json",
"description": "Model Blueprint Tags"
},
{
"filename": "../supportingFiles/assetblueprinttagrules.json",
"description": "Asset Blueprint Tag Rules"
},
{
"filename": "../supportingFiles/modelblueprinttagrules.json",
"description": "Model Blueprint Tag Rules"
},
{
"filename": "../supportingFiles/ruletagassociations.json",
"description": "Rule Tag Associations"
},
{
"filename": "../supportingFiles/diagnostics.json",
"description": "Diagnostic Rules"
}
],
"inputs": [
{
"name": "temperature",
"unit": "",
"description": "temperature",
"dataType": "Double"
},
{
"name": "pressure",
"unit": "",
"description": "pressure",
"dataType": "Double"
}
],
"constants": [
{
"value": 0.92,
"uri": "",
"name": "threshold",
"unit": "",
"description": "threshold",
"dataType": "Double"
}
],
"outputs": [
{
"name": "power",
"unit": "",
"description": "",
"dataType": "Double"
},
{
"name": "heatrate",
"unit": "",
"description": "",
"dataType": "Double"
},
{
"name": "availability",
"unit": "",
"description": "",
"dataType": "Double"
}
]
// END Mandatory
"outputEvents" :[
"name": "<your alert template name. Must be present in the tenant. Validated. >",
]
}
}deployments.json
This file defines the ingestion metadata contract for all deployments. Each deployment .json file must begin with the prefix deployment_. This file contains the following information required to configure analytic deployments:
- Link to template artifact
- Name for this deployment
- Author of this deployment
- Asset information - which asset this analytic is applied to
- Link to IOMapping artifact files.
The following code snippet indicates the .json structure with required (mandatory) field configurations. The file must conform to the schema indicated in the code snippet.
{
@type: "deploymentSsRmMetadata", // Mandatory
"contractVersion": "1.0.0", //Mandatory
"name":"<your deployment name>", //Mandatory
"templateType": "Analytic", /* Analytic or Orchestration */ //Mandatory
"templateName": "<your template name from the template.json ingested" //Mandatory
"templateVersion": "<version>",
"isReadOnly":true, //Mandatory - If set to false, the deployment configuratons can be modified in the Analytic UI.
"keyValueStore" :{
"runtimeAnalyticUri":"<your url CAF will call to get custom data for deployment>", //Mandatory for RM Smart Signal Ex: /analyticIntance/13a47853-0804-4972-ac33-b16d33336351)
targetCardType:"SmartSignal", //Mandatory
"<key1>":"<value>",
...
},
"entityFilterFileName": "../entityFilter.json", //Mandatory, this is the relative path of the entityFilter.json
"deploymentSteps": [
{
"analyticName": "<name>", //Mandatory for Template Type "Orchestration"
"analyticVersion": "<analyticVersion>",
"ioMappingFiles": [
"../ioMappings/IOMappingMetadata1.json",
"../ioMappings/IOMappingMetadata2.json" // Multiple only if there is iterations.
]
}
]
"deployParams": { /* Scheduling and data parameter information can be given here, This is not required in case of RM analytics */
"analyticArtifactVersion": null,
"repeatData": null,
"startTime": "1492723560",
"endTime": "1493069160",
"samplingInterval": null,
"sampleDuration": null,
"startOffset": null,
"deployType": "DeployOnDemand",
"doExecuteJob":false,
"doDeployPerAsset": true
},
"doDeploy": true
}ioMapping.json
Contains the mapping information for inputs and outputs in the template to asset tags.
The following code snippet indicates the .json structure with required (mandatory) field configurations. The file must conform to the schema indicated in the code snippet.
{
"@type": "ioMappingSsRmMetaData", // Mandatory
"contractVersion": "1.0.0", //Mandatory
"name": "ioMappingSsRm1", // Mandatory
"description": "description",
"inputsToDataSource": [ //Mandatory Start here
{
"portName": "EXHAUST_STEAM_TEMP_1",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "EXHAUST_STEAM_TEMP_1"
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "GROSS_POWER",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "GROSS_POWER"
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "INLET_STEAM_TEMP_1",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "INLET_STEAM_TEMP_1"
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "MODE_TAG_1",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "MODE_TAG_1"
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "INLET_STEAM_PRESS_1",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "INLET_STEAM_PRESS_1"
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "EXHAUST_STEAM_PRESS_1",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "EXHAUST_STEAM_PRESS_1"
},
"assetSourceKeyToDataSources": {}
}
],
"constantsToDataSource": [
{
"portName": "TURBINE_EXHAUST_STEAM_QUALITY",
"commonDataSource": {
"@type": "ioDataSourceValueCommon",
"dataType": "Integer",
"value": 0.92
},
"assetSourceKeyToDataSources": {}
},
{
"portName": "MODE_TAG_1_THRESHOLD",
"commonDataSource": {
"@type": "ioDataSourceValueCommon",
"dataType": "Double",
"value": 30.0
}
}
],
"outputsToDataSource": [
{
"portName": "MODE_CV",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "MODE_CV"
}
},
{
"portName": "TURBINE_PRESS_RATIO_CV",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "TURBINE_PRESS_RATIO_CV"
}
},
{
"portName": "TURBINE_EXHAUST_STEAM_QUALITY_CV",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "TURBINE_EXHAUST_STEAM_QUALITY_CV"
}
},
{
"portName": "TURBINE_EFFICIENCY_CV",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "TURBINE_EFFICIENCY_CV"
}
},
{
"portName": "TURBINE_TEMP_RATIO_CV",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "TURBINE_TEMP_RATIO_CV"
}
},
{
"portName": "CVMEHtag",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "CVMEHtag"
}
},
{
"portName": "CVMEhTagF",
"commonDataSource": {
"@type": "ioDataSourceTagCommon",
"entityType": "Asset",
"tagName": "CVMEhTagF"
}
}
] //Mandatory Ends here
}entityFilter.json
This entity filter is created and is referenced in the deployment as the asset selection for the deployment.
The following code snippet indicates the .json structure with required (mandatory) field configurations. The file must conform to the schema indicated in the code snippet.
{
"contractVersion": "1.0.0",
"entityFilter": {
"name": "XE7FA_297479_3504_Ingestion",
"entityFilterConditions": [
{
"entityFilterFieldName": "Asset Name",
"operator": "=",
"value": "XE7FA_297479_3504"
}
]
}
}Upload Timeseries Data through CSV
Enables you to upload a .csv file consisting of tag data in order into Timeseries data store, Asset URIs, and Tag Names/IDs corresponding to the ingested tag data.
Before You Begin
- The following permissions must be added for the logged in user for the specific tenant:
- View Ingestion
- Manage Ingestion
- Prepare the CSV file consisting of tag data to be ingested into Timeseries data store in the required format.
- Make sure that you have the required assets in the system with all the required tags and attributes needed for I/O mapping.
- For each analytic being deployed to a set of assets, make sure you have created the analytic template, and that you have defined the analytic inputs, constants, outputs, and output events as needed to run the analytic.
- Metadata corresponding to header fields of uploaded CSV file.
Procedure
- In the heading, select
 .The Upload CSV window appears.
.The Upload CSV window appears. - Select
 .The ingestion is created and the Ingestion Results window appears.
.The ingestion is created and the Ingestion Results window appears.
Results
| Ingestion Status | Description | Create Deployment Allowed | Delete Allowed |
|---|---|---|---|
| Submitted | File has been uploaded and accepted by Timeseries. Check ingestion error message for more info. | Yes | Yes |
| Completed | File has been processed by Timeseries. | Yes | Yes |
| In Progress | File has been processed by CAF. Data has been persisted to Analytics database. | No | No |
| Failed | Analytics or Timeseries had issue processing file. Deployment is allowed as it may be a gateway issue. If it is a large file, do not upload again, if not necessary. Check ingestion error message for more information. | Yes | Yes |
What To Do Next
Download Sample CSV with Timeseries Data
About This Task
Procedure
- In the heading, select
 .A zip file is downloaded that contains CSV template for Timeseries data ingestion.
.A zip file is downloaded that contains CSV template for Timeseries data ingestion.
What To Do Next
Create Deployments using Ingested Timeseries Data
Before You Begin
Upload the CSV containing the Timeseries data.
About This Task
Procedure
- In the heading, select
 .The Create Deployment window appears.
.The Create Deployment window appears. - Select
 .The Deployment is created successfully.
.The Deployment is created successfully.
Results
Delete Ingestions
Before You Begin
Upload the CSV with the ingestion data.
About This Task
Procedure
- In the heading, select
 .Note: If there is an associated deployment with the ingestion, then the deployment must be deleted before the ingestion is deleted.The ingestion record is deleted from the ingestion page.
.Note: If there is an associated deployment with the ingestion, then the deployment must be deleted before the ingestion is deleted.The ingestion record is deleted from the ingestion page.
What To Do Next
CSV Ingestion File Format
Analytics supports only CSV file extensions for ingesting the timeseries data.
| Asset Source Key | Time Stamp | Tag Id | Data Value | Data Type | Quality |
|---|---|---|---|---|---|
The following table describes the ingestion file columns:
| Column Number | Column Header | Description |
|---|---|---|
| 1 | Asset Source Key | Must be unique per classification and can only contain alphabets (a-z, A-Z), digits (0-9), underscores _, hyphens -, dots . and quotes " |
| 2 | Time Stamp | UTC format is Example: yyyy-mm-ddThh:mm:ss.sssZ 2022-07-28T10:07:10.000Z |
| 3 | Tag Id | Must be the source key ID of the tag and can only contain alphabets (a-z, A-Z), digits (0-9), underscores _, hyphens -, dots . and quotes " |
| 4 | Data Value | Actual value of the data. It should consists of < 256 characters. |
| 5 | Data Type | Float, Int, Boolean, String |
| 6 | Quality | Good, Bad |
| ABC_LHK_B02_INV01 | 2020-06-27T12:00:00.001Z | ABC_LHK_B02_INV01.DC_POWER | 100.1 | Float | GOOD |